---
# Só mude aqui!!!!
author: "Wadmilson Costa da Fonseca e Cruz"
title: "Relatorio do experimento da cataputa"
bibliography: referencias.bib
# A partir daqui nao faca alteracoes!!!!!
link-citations: true
csl: associacao-brasileira-de-normas-tecnicas-ipea.csl
subtitle: "<a href='https://bendeivide.github.io/courses/epaec/' target='_blank'>Estatística e Probabilidade</a> </br> <a href='https://bendeivide.github.io' target='_blank'>Prof. Ben Dêivide (DEFIM/CAP/UFSJ)</a>"
include-before-body: header.html
date: now
date-format: "DD/MM/YYYY, HH:mm"
lang: pt-BR
format:
html:
toc: true
number-sections: true
theme: bootstrap
#css: styles.css
code-fold: true
code-tools: true
execute:
echo: true
warning: false
message: false
---
## 📌 Introdução
Como forma de aplicar os conceitos que estudamos em aula de estatistica de manera pratica, realizamos 40 lançamentos utilizando uma catapulta, midindo e anotando a distancia alcançada em cada tentativa.
A partir desses valores coletados, analisaremos os dados aplicando os conceitos de medidas de posição e disperção, e a realizaremos sua tabulação e representação grafica, tanto com dados agrupados em intervalos de classe quanto sem.
## 🎯 Objetivo
O foco deste relatorio, consiste em realizar a descrição dos dados coletados por meio de tabulação e apresentação gráfica, bem como calcular as medidas de posição e de dispersão, tanto com ou sem agrupamento de dados em intervalos de classe ou não, discutindo as diferenças observadas entre os resultados.
Além disso, objetivamos analisar a assimetria e a curtose do conjunto de dados, apresentando justificativas sobre a importância dessas medidas para a descrição estatística, bem como indicar possíveis falhas ocorridas durante a execução do experimento.
## ⚙️ Metodologia
O experimento foi realizado em sala de aula. Formamos dois grupos, onde um realizou os lançamentos primeiro e, depois, o outro. No primeiro grupo, as funções foram divididas da seguinte forma: Maria Eduarda e Marcos ficaram responsáveis pela execução dos lançamentos, Igor e o Lucas, pela medição das distancias, João Pedro, pela captura das fotos, e Wadmilson, pela coleta e anotação dos dados.
Utilizamos uma catapulta, uma trena e uma bolinha para a realização do experimento. A catapulta foi posicionada sobre uma mesa com altura de 78 cm, e com a trena medimos a distancia alcançada em cada lançamento.
Na catapulta, utilizamos diferentes combinações de variaveis, sendo o A+ (segundo pino,de cima para baixo ), o A-(primeiro pino, de cima para baixo), o O- (terceiro pino, de cima para baixo), e B+ (angulo de 45 graus), conforme mostra nas imagens que se seguem.
{width=50%}{width=50%}{width=50%}
Para torna a medição mais simples e menos trabalhosa, marcamos uma distancia inicial de 250 cm (2,5 metros) do pé da mesa, na direção do espaço que a bolinha percorreria após ser lançada, como ponto fixo de referencia. Assim como observaremos na imagem a seguir.
{width=40%}
Para obter a distancia total de cada lançamento, somamos essa distancia fixa com a distancia adicional registrada em cada lançamento. Ao final, Marcos organizou todas as medidas coletadas e eviou os dados amostrais para o professor, e para os demais integrantes do grupo.
Assim as distancias totais em centimetros, que coletamos após os 40 lançamentos foram: 346, 339, 339, 332, 293, 368, 365, 341, 329, 339, 323, 335, 369, 347, 352, 340, 338, 350, 341, 336, 320, 341, 330,328, 336, 318, 275, 329, 357, 317, 302, 331, 359, 333, 324, 334, 339, 332, 331, 320.
## Análise e discussão dos resultados
### Tabulação e apresentação grafica de dados brutos sem intervalos de classe e suas medidas
Com os dados coletados, faremos sua tabulação e apresentação grafica, tanto agrupados em intervalos de classes quanto sem agrupamento. Em seguida, calcularemos as medidas de posição e dispersão para cada um dos casos.
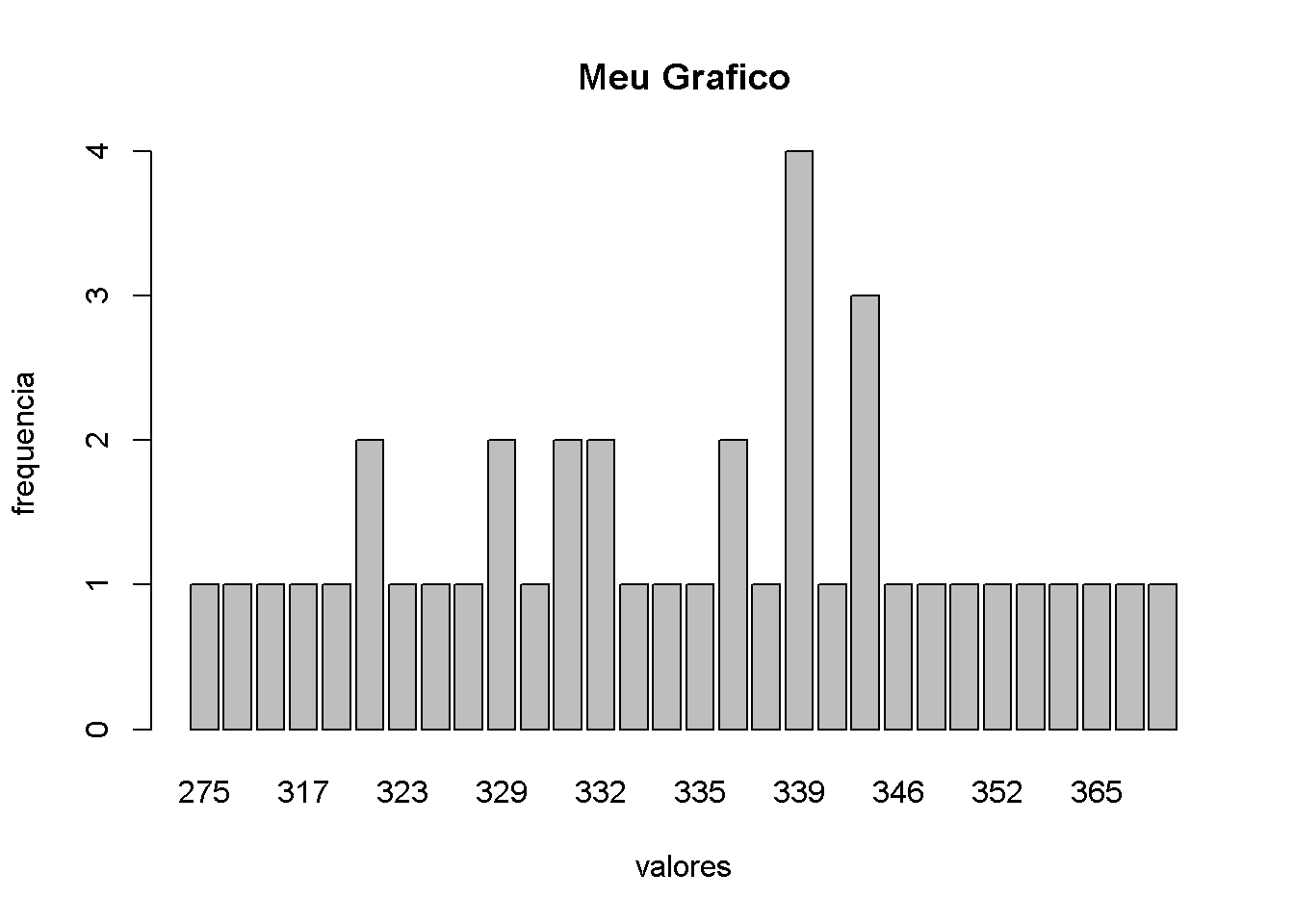
Primeiramente, apresentaremos a tabulação e apresentação grafica com dados brutos, sem intervalos de classes, juntamente com suas medidas de posição e dispersão.
```{r}
#|code-fold: True
#|warning: False
library(leem)
dados <- c(346, 339, 339, 332, 293, 368, 365, 341, 329, 339, 323, 335, 369, 347, 352, 340, 338, 350, 341, 336, 320, 341, 330,328, 336, 318, 275, 329, 357, 317, 302, 331, 359, 333, 324, 334, 339, 332, 331, 320)
# Transformar para dados discretos/sem agrupamento
dados_sem_agrupo <- new_leem(dados, variable = 'discrete')
# Tabela de frequencia
tabela_sem<- tabfreq(dados_sem_agrupo, ncol = 4)
tabela_sem
# Criando o graficorafico
Grafico <- barplot(table(dados), main = 'Meu Grafico', xlab = 'valores', ylab = 'frequencia')
# MEDIDAS DE POSIÇÃO
#| code-fold: True
media <- mean(dados)
mediana <- median(dados)
# Calcula a moda
tabela <- table(dados)
moda <- as.numeric(names(tabela[tabela == max(tabela)]))
cat("--- MEDIDAS DE POSIÇÃO ---\n")
cat("Média Aritmética:", media, "\n")
cat("Mediana:", mediana, "\n")
cat("Moda:", moda, "\n\n")
# MEDIDAS DE DISPERSÃO
#| code-fold: True
amplitude_total <- max(dados) - min(dados)
variancia <- var(dados)
desvio_padrao <- sd(dados)
coeficiente_variacao <- (desvio_padrao / media) * 100
erro_padrao_media <- desvio_padrao / sqrt(length(dados))
cat("--- MEDIDAS DE DISPERSÃO ---\n")
cat("Amplitude Total:", amplitude_total, "\n")
cat("Variância:", variancia, "\n")
cat("Desvio Padrão:", desvio_padrao, "\n")
cat("Coeficiente de Variação (%):", coeficiente_variacao, "\n")
cat("Erro Padrão da Média:", erro_padrao_media, "\n")
```
### Interpretando os resultados obtidos
Os valores da média (334,45) e da mediana (335,5) são muito próximos, indicando que os dados são simétricos e bem distribuídos, sem valores extremos que alterem o centro da distribuição.
A moda é 339, pois este foi o valor que mais se repetiu na amostra, ocorrendo com maior frequencia.
A amplitude Total deu 94, pois o valor máximo é 94 unidades superior ao valor mínimo, mostrando a extensão total do intervalo coberto pelos seus dados. A variância foi de 337,48, uma medidaque expressa o grau de dispersão, quanto maior esse valor, mais afastados da media estão os dados, refletetindo o cálculo das distâncias quadradas em relação ao centro.
O Desvio Padrão de 18,37 e o Coeficiente de Variação de apenas 5,49% indicam baixa dispersão e alta homogeneidade, ou seja, os dados são consistentes e poucos variaveis em torno da media.
O erro padrão da média de 2,9 significa que o valor de 334,45 é bastante preciso, representando muito bem a realidade dos dados com uma pequena margem de erro.
### Tabulação e apresentação grafica de dados agrupados com intervalos de classe e suas medidas
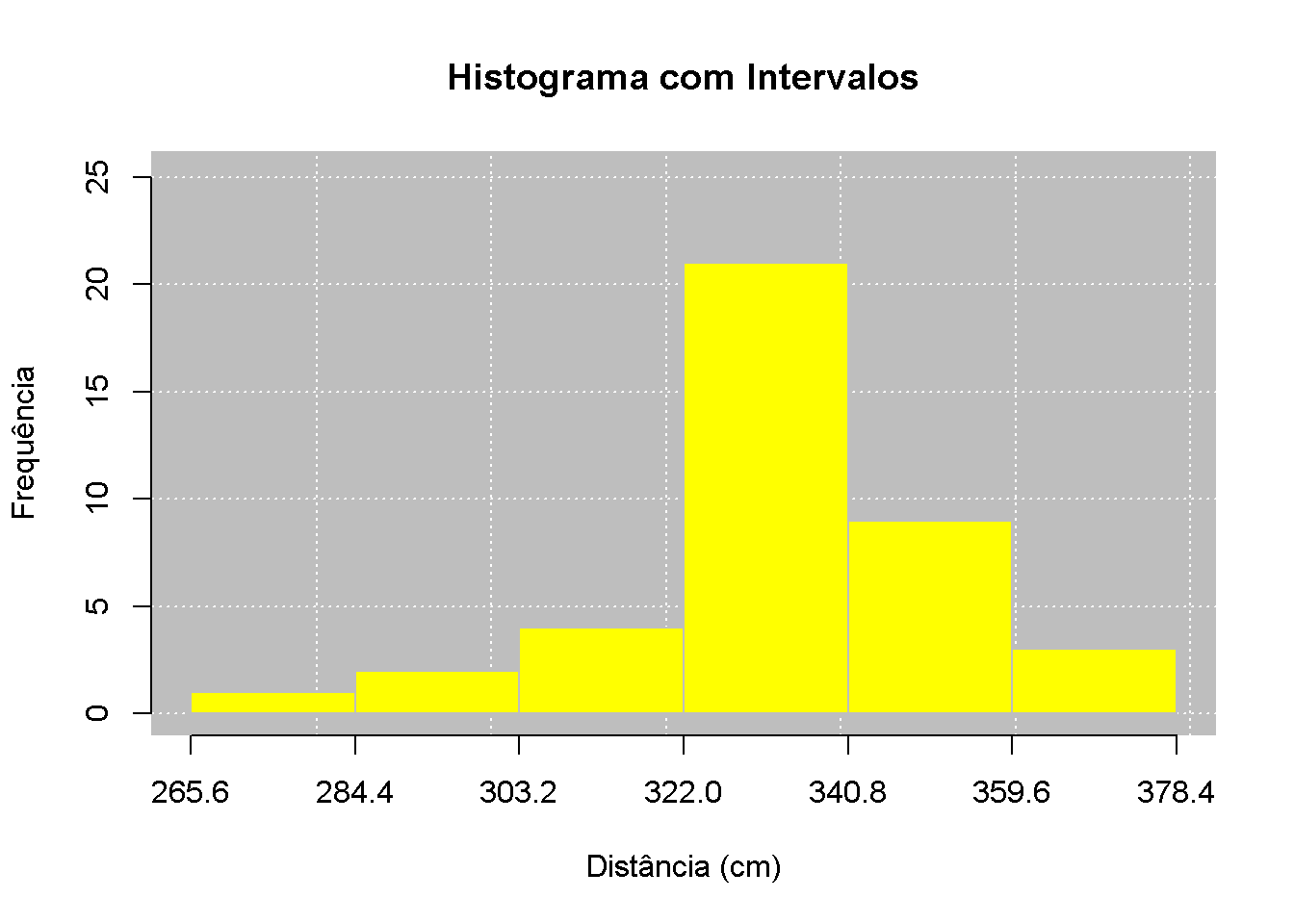
Agora, faremos a tabulação e a apresentação grafica com dados agrupados em intervalos de classe, bem como o calculo das respetivas medidas de posição e dispersão.
```{r}
#| code-fold: true
#| warning: false
library(leem)
dados <- c(346, 339, 339, 332, 293, 368, 365, 341, 329, 339, 323,
335, 369, 347, 352, 340, 338, 350, 341, 336, 320, 341,
330, 328, 336, 318, 275, 329, 357, 317, 302, 331, 359,
333, 324, 334, 339, 332, 331, 320)
# Transformar para dados contínuos/com agrupamento
dados_com_agrupo <- new_leem(dados, variable = "continuous")
# Tabela de frequência
tabela_com <- tabfreq(dados_com_agrupo)
tabela_com
### Gráfico (Histograma)
#| code-fold: true
barplot(tabela_com, main = "Histograma com Intervalos",
xlab = "Distância (cm)", ylab = "Frequência", col = "lightblue")
### Medidas de Posição
#| code-fold: true
media <- mean(dados)
mediana <- median(dados)
moda <- as.numeric(names(which.max(table(dados))))
# --- MEDIDAS DE DISPERSÃO ---
amplitude <- max(dados) - min(dados)
variancia <- var(dados)
desvio_padrao <- sd(dados)
coeficiente_variacao <- (desvio_padrao / media) * 100
erro_padrao_media <- desvio_padrao / sqrt(length(dados))
# --- EXIBIR TUDO ---
cat("\n\n")
cat("MEDIDAS DE POSIÇÃO\n")
cat("Média:", round(media, 2), "\n")
cat("Mediana:", mediana, "\n")
cat("Moda:", moda, "\n")
cat("MEDIDAS DE DISPERSÃO\n")
cat("Amplitude Total:", amplitude, "\n")
cat("Variância:", round(variancia, 2), "\n")
cat("Desvio Padrão:", round(desvio_padrao, 2), "\n")
cat("Coef. Variação:", round(coeficiente_variacao, 2), "%\n")
cat("Erro Padrão Média:", round(erro_padrao_media, 2), "\n")
cat("\n")
```
### Interpretando os resultados obtidos
Os resultados obtidos com os dados agrupados foram muito próximos aos encontrados na análise sem agrupamento. A média de 334,45 e a mediana de 335,5 continuam muito próximas, confirmando a simetria dos dados. A moda de 339 permanece como o valor mais frequente.
O desvio padrão de 18,37 e o coeficiente de variação de 5,49% indicam, novamente, baixa dispersão e alta homogeneidade, mostrando que os valores são consistentes e próximos uns dos outros, independentemente da forma como foram organizados
Ao analisar os resultados obtidos, observa-se que os valores calculados foram extremamente próximos. Isso ocorreu porque os dados se distribuíram de forma bastante uniforme dentro das classes e porque utilizamos os pontos médios como base para os cálculos.
O agrupamento dos dados facilita a visualização gráfica e a leitura da tabela, sem perder a precisão das informações principais. Porém, trata-se sempre de uma estimativa: perdemos um pouco da identidade individual de cada valor em troca de uma visão geral. Já os dados brutos oferecem exatidão total.
A seguir, abordaremos os coeficientes de assimetria e curtose.
### Coeficiente de Assimetria (Pearson)
A assimetria mede se os dados estão concentrados à esquerda, à direita ou se distribuem de forma simétrica em relação à média.
Cálculo:
```{r}
# Usando os valores que já calculamos
media <- 334.45
mediana <- 335.5
desvio_padrao <- 18.37
# Fórmula: Sk = 3 * (Média - Mediana) / Desvio Padrão
sk <- 3 * (media - mediana) / desvio_padrao
# Mostrando o resultado
cat("--- Coeficiente de Assimetria (Pearson) ---\n")
cat("Sk =", sk, "\n")
```
Como o valor calculado é -0,17, muito próximo de zero, a distribuição apresenta assimetria praticamente Nula / levemente negativa.
O histograma tem formato muito próximo a uma "curva de sino" perfeita.
### Coeficiente de Curtose
A curtose mede o "grau de achatamento" ou "pontuação" da curva de frequência, comparando-a com a Curva Normal.
Ela é classificada em:
- mesocúrtica: curva normal (padrão);
- leptocúrtica: curva mais "alta e pontuda" (dados muito concentrados);
- platicúrtica: curva mais "baixa e achatada" (dados muito espalhados);
Com base na dispersão e quartis, observa-se que os dados estão bem concentrados em torno da média, com caudas adequadas, logo, a distribuição é mesocúrtica, pois seu formato é muito semelhante ao da distribuição normal padrão.
Essas medidas são importantes porque a média e o desvio padrão sozinhos não revelam toda a informação. Saber que a distribuição é simétrica confirma que a média é uma boa medida representativa dos dados, caso fosse muito assimétrica, a mediana seria a melhor opção.
Muitos modelos e testes estatistico, como o Teste T ou Análise de Regressão, exigem que os dados tenham distribuição próxima da normal, e o valor -0,17 obtido valida o uso dessas ferramentas.
Conhecer a forma da curva ajuda a compreender o comportamento do fenômeno estudado, neste caso, os valores são consistentes e bem distribuídos em torno do centro.
### Possíveis falhas de execução do experimento
Durante a coleta dos dados, observou-se que os resultados do lançamento 5, 27 apresentaram valores muito inferiores aos demais, indicabdo provaveis erro na execução.
Embora sejam esperadas pequenas variações entre os lançamentos, a diferença observada foi excessiva.
Além disso, ocorreram falhas na medição por parte da equipe: nem todas as marcções foram feitas exatamente no ponto de impacto da bolinha. A trena ficou ligeiramente deslocada da referencia e, em alguns casos, oponto registrado não correspondia ao primeiro contacto entre da bolinha com o solo.
## 📖 Referências
R CORE TEAM. R: A Language and Environment for Statistical Computing. Vienna: R Foundation for Statistical Computing, 2025. Disponível em: <https://www.R-project.org/>.
BRITO, Ben Dêivide. leem: Learning from Elementary Statistics Methodology. R package version 1.1.3, 2023. Disponível em: <https://bendeivide.github.io/leem/>.
MORETTIN, Pedro Alberto; BUSSAB, Wilton de Oliveira. Estatística Básica. 9. ed. São Paulo: Saraiva, 2017.
TRIOLA, Mario F. Introdução à Estatística. 12. ed. Rio de Janeiro: LTC, 2017.